반응형
# 1단계
# 첫번째 글 - 제목, 링크, 날짜, 카테고리, 답변수반응형
import requests
from bs4 import BeautifulSoup
respone = requests.get('https://kin.naver.com/search/list.naver?query=%EC%82%BC%EC%84%B1%EC%A0%84%EC%9E%90')
html = respone.text
soup = BeautifulSoup(html, 'html.parser')
#클래스안에 띄어쓰기가 되어 있는 경우 클래스가 여러개 부여되어 있는것
#띄어쓰기가 있을시 :, . 앞에 \를 붙여준다. 파이선에서는 \\을 넣어준다.(문자인식 때문)
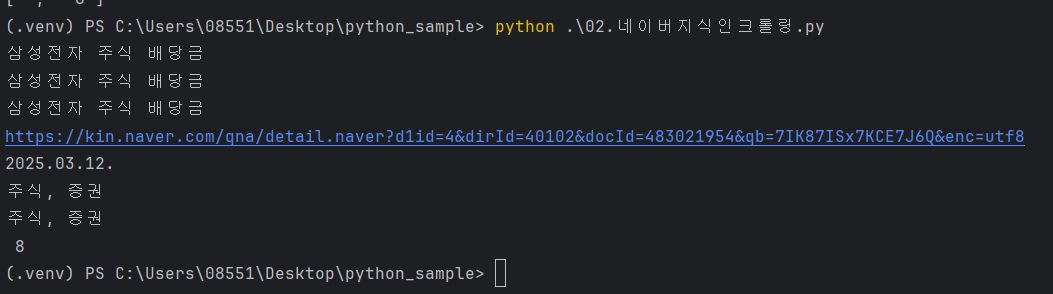
print(soup.select_one("._nclicks\\:kin\\.txt").text)
print(soup.select_one("._searchListTitleAnchor").text)
print(soup.select_one("._nclicks\\:kin\\.txt._searchListTitleAnchor").text)
print(soup.select_one("._nclicks\\:kin\\.txt").attrs['href'])
print(soup.select_one(".txt_inline").text)
print(soup.select_one(".txt_g1._nclicks\\:kin\\.cat2").text)
print(soup.select_one(".txt_block > a:nth-of-type(2)").text)
print(soup.select_one(".txt_block > span:nth-of-type(2)").text.split('답변수')[1])
반응형
'IT > Python' 카테고리의 다른 글
| [Python-크롤링] 웹사이트 파라미터 종류가 많을때 크롤링 하는 방법 2단계 (1) | 2025.05.01 |
|---|---|
| [Python-크롤링] 웹사이트 파라미터 종류가 많을때 크롤링 하는 방법 1단계 (0) | 2025.04.30 |
| [Python - 크롤링] 네이버 증권 뉴스 엑셀파일 저장하기 (0) | 2025.04.25 |
| [Python - 크롤링] 한국 주식 종가 갖고 오는 프로그램 코드 (0) | 2025.04.25 |
| [파이썬-크롤링] 네이버 증권 뉴스 크롤링 하기 (0) | 2025.04.24 |